











Матушкин Андрей Николаевич
Президент IAPD
Staff member
Private access level
Full members of NP "MOD"
I’ll calculate you over networks: we use the APIs of the largest social networks for my own selfish purposes.

It's no secret that modern social networks are huge databases containing a lot of interesting information about the privacy of their users. You won’t get much data through the web-face, but each network has its own API ... So let's see how this can be used to find users and collect information about them.
There is a discipline in American intelligence such as OSINT (Open source intelligence), which is responsible for the search, collection and selection of information from public sources. One of the largest providers of publicly available information includes social networks. Indeed, almost every one of us has an account (and someone has more than one) in one or more social networks. Here we share our news, personal photos, tastes (for example, like something or joining a group), the circle of our acquaintances. And we do this of our own free will and practically do not think about the possible consequences. The pages of the magazine have repeatedly considered how to extract interesting data from social networks using various tricks. Usually, for this it was necessary to manually perform some kind of manipulation. But for successful reconnaissance, it is more logical to use special utilities. There are several open source utilities that allow you to pull information about users from social networks.
Creepy
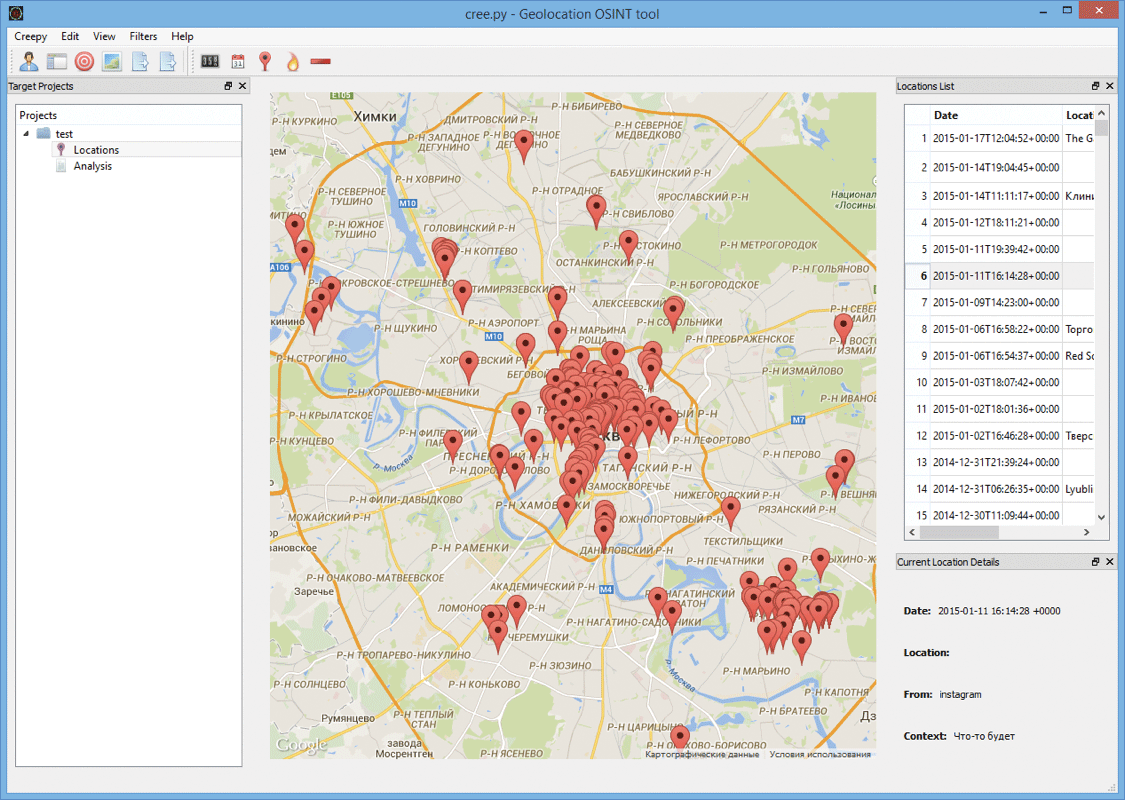
One of the most popular is Creepy. It is designed to collect geolocation information about the user based on data from his Twitter, Instagram, Google+ and Flickr accounts. The advantages of this tool, which is standardly included in Kali Linux, include an intuitive interface, a very convenient process of obtaining tokens for using API services, as well as displaying the results found by labels on the map (which, in turn, allows you to track all user movements). The disadvantages I would include a rather weak functionality. Tulsa knows how to collect geotags for these services and display them on a Google map, shows who and how many times the user retweeted, considers statistics on the devices from which tweets were written, as well as the time they were published. But due to the fact that this is an open source tool, its functionality can always be expanded by yourself.
We will not consider how to use the program - everything is perfectly shown in the official video, after watching which there should not be any questions about working with the tool.
fbStalker
Two other tools that are less known, but have strong functionality and deserve your attention are fbStalker and geoStalker.
fbStalker is designed to collect user information based on its Facebook profile. Allows you to get the following data:
videos, photos, user posts;
who and how many times liked his posts;
geolocation of photos;
statistics of comments on his posts and photos;
the time that he usually visits online.
For this tool to work, you will need Google Chrome, ChromeDriver, which is installed as follows:
wget [DLMURL] https://goo.gl/Kvh33W [/ DLMURL]
unzip chromedriver_linux32_23.0.1240.0.zip
cp chromedriver / usr / bin / chromedriver
chmod 777 / usr / bin / chromedriver
In addition, you will need installed Python 2.7, as well as pip to install the following packages:
pip install pytz
pip install tzlocal
pip install termcolor
pip install selenium
pip install requests --upgrade
pip install beautifulsoup4
And finally, you need a library for parsing GraphML files:
git clone [DLMURL] https://github.com/hadim/pygraphml.git [/ DLMURL]
cd pygraphml
python2.7 setup.py install
After that, it will be possible to fix the `fbstalker.py`, indicating there your soap, password, username, and start the search. Using the tool is quite simple:
python fbstalker.py -user [username of interest]
geoStalker
geoStalker is much more interesting. He collects information on the coordinates that you gave him. For example:
local Wi-Fi-points based on the base `wigle.net` (in particular, their` essid`, `bssid`,` geo`);
Checks from Foursquare;
Instagram and Flickr accounts from which photos were posted with reference to these coordinates;
all tweets made in the area.
For the tool to work, as in the previous case, you will need Chrome & ChromeDriver, Python 2.7, pip (to install the following packages: google, python-instagram, pygoogle, geopy, lxml, oauth2, python-linkedin, pygeocoder, selenium, termcolor, pysqlite , TwitterSearch, foursquare), as well as pygraphml and gdata:
git clone [DLMURL] https://github.com/hadim/pygraphml.git [/ DLMURL]
cd pygraphml
python2.7 setup.py install
wget https://gdata-python-client.googlecode. ... .18.tar.gz
tar xvfz gdata-2.0.18.tar.gz
cd gdata-2.0.18
python2.7 setup.py install
After that, edit `geostalker.py`, filling out all the necessary API keys and access tokens (if for any social network this data is not specified, then it simply will not participate in the search). After that, run the tool with the command `sudo python2.7 geostalker.py` and specify the address or coordinates. As a result, all data is collected and placed on a Google map, and also saved in an HTML file.
Move on to action
Before that, it was about ready-made tools. In most cases, their functionality will be lacking and you will either have to modify them or write your own tools - all popular social networks provide their APIs. Usually they appear as a separate subdomain to which we send GET requests, and in response we get XML / JSON responses. For example, for "Instagram" it is `api.instagram.com`, for" Contact "it is` api.vk.com`. Of course, most of these APIs have their own libraries of functions for working with them, but we want to understand how it works, and to make the script heavier with unnecessary external libraries due to one or two functions not comme il faut. So, let's take and write our own tool that would allow us to search for photos from VK and Instagram based on the given coordinates and time interval.
Using the documentation for API VK and Instagram, we make requests for a list of photos by geographical information and time.
Instagram API Request:
url = "https://api.instagram.com/v1/media/search?"
+ "lat =" + location_latitude
+ "& lng =" + location_longitude
+ "& distance =" + distance
+ "& min_timestamp =" + timestamp
+ "& max_timestamp =" + (timestamp + date_increment)
+ "& access_token =" + access_token
Vkontakte API Request:
url = "https://api.vk.com/method/photos.search?"
+ "lat =" + location_latitude
+ "& long =" + location_longitude
+ "& count =" + 100
+ "& radius =" + distance
+ "& start_time =" + timestamp
+ "& end_time =" + (timestamp + date_increment)
The variables used here are:
location_latitude - geographical latitude;
location_longitude - geographical longitude;
distance - search radius;
timestamp - initial border of the time interval;
date_increment - the number of seconds from the start to the end of the time interval;
access_token - developer token.
As it turned out, access to Instagram requires access_token. It’s easy to get it, but you’ll have to get a little confused (see sidebar). Contact is more loyal to strangers, which is very good for us.
Getting Instagram Access Token
To get started, register on instagram. After registration, go to the following link:
instagram.com/developer/clients/manage
Click ** Register a New Client **. Enter the phone number, wait for the message and enter the code. In the window for creating a new client that opens, we need to fill in the important fields for us as follows:
OAuth redirect_uri: localhost
Disable implicit OAuth: checkmark must be unchecked
The remaining fields are filled arbitrarily. Once everything is full, create a new client. Now you need to get the token. To do this, enter the following URL in the address bar of the browser:
[DLMURL] https://instagram.com/oauth/authorize/?client_id= [/ DLMURL] [CLIENT_ID] & redirect_uri = http: // localhost / & response_type = token
where instead of [CLIENT_ID] specify the Client ID of the client you created. After that, follow the link, and if you did everything correctly, then you will be forwarded to localhost and Access Token will be written in the address bar.
http: // localhost / # access_token = [Access Token]
You can read more about this method of obtaining a token at the following link: jelled.com/instagram/access-token.
Automate the process
So, we learned how to make the necessary queries, but manually parsing the server response (in the form of JSON / XML) is not the coolest task. It is much more convenient to make a small script that will do this for us. We will use again Python 2.7. The logic is as follows: we are looking for all the photos that fall in a given radius relative to the given coordinates in a given period of time. But consider one very important point - a limited number of photos are displayed. Therefore, for a large period of time, you will have to make several requests with intermediate time intervals (just date_increment). Also take into account the accuracy of the coordinates and do not specify a radius of several meters. And do not forget that time must be specified in timestamp.
We begin to code. First, we’ll connect all the libraries we need:
import httplib
import urllib
import json
import datetime
We write functions for receiving data from the API via HTTPS. Using the passed arguments to the function, we compose a GET request and return the server response as a string.
def get_instagram (latitude, longitude, distance, min_timestamp, max_timestamp, access_token):
get_request = '/ v1 / media / search? lat =' + latitude
get_request + = '& lng =' + longitude
get_request + = '& distance =' + distance
get_request + = '& min_timestamp =' + str (min_timestamp)
get_request + = '& max_timestamp =' + str (max_timestamp)
get_request + = '& access_token =' + access_token
local_connect = httplib.HTTPSConnection ('api.instagram.com', 443)
local_connect.request ('GET', get_request)
return local_connect.getresponse (). read ()
def get_vk (latitude, longitude, distance, min_timestamp, max_timestamp):
get_request = '/method/photos.search?lat=' + location_latitude
get_request + = '& long =' + location_longitude
get_request + = '& count = 100'
get_request + = '& radius =' + distance
get_request + = '& start_time =' + str (min_timestamp)
get_request + = '& end_time =' + str (max_timestamp)
local_connect = httplib.HTTPSConnection ('api.vk.com', 443)
local_connect.request ('GET', get_request)
return local_connect.getresponse (). read ()
We also find a small function to convert timestamp to human view:
def timestamptodate (timestamp):
return datetime.datetime.fromtimestamp (timestamp) .strftime ('% Y-% m-% d% H:% M:% S') + 'UTC'
Now we write the main logic for image search, after dividing the time interval into parts, we save the results in an HTML file. The function looks cumbersome, but the main difficulty in it is dividing the time interval into blocks. The rest is just parsing JSON and storing the necessary data in HTML.
def parse_instagram (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, access_token):
print 'Starting parse instagram ..'
print 'GEO:', location_latitude, location_longitude
print 'TIME: from', timestamptodate (min_timestamp), 'to', timestamptodate (max_timestamp)
file_inst = open ('instagram _' + location_latitude + location_longitude + '. html', 'w')
file_inst.write (' <html> ')
local_min_timestamp = min_timestamp
while (1):
if (local_min_timestamp> = max_timestamp):
break
local_max_timestamp = local_min_timestamp + date_increment
if (local_max_timestamp> max_timestamp):
local_max_timestamp = max_timestamp
print timestamptodate (local_min_timestamp), '-', timestamptodate (local_max_timestamp)
local_buffer = get_instagram (location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp, access_token)
instagram_json = json.loads (local_buffer)
for local_i in instagram_json ['data']:
file_inst.write ('
')
file_inst.write (' <img src='+local_i['images']['standard_resolution']['url']+'>
')
file_inst.write (timestamptodate (int (local_i ['created_time']))) + '
')
file_inst.write (local_i ['link'] + '
')
file_inst.write ('
')
local_min_timestamp = local_max_timestamp
file_inst.write (' </html> ')
file_inst.close ()
The HTML format was chosen for a reason. It allows us not to save pictures separately, but only indicate links to them. When the page starts, the results in the image browser are automatically loaded.
We are writing exactly the same function for “Contact”.
def parse_vk (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment):
print 'Starting parse vkontakte ..'
print 'GEO:', location_latitude, location_longitude
print 'TIME: from', timestamptodate (min_timestamp), 'to', timestamptodate (max_timestamp)
file_inst = open ('vk _' + location_latitude + location_longitude + '. html', 'w')
file_inst.write (' <html> ')
local_min_timestamp = min_timestamp
while (1):
if (local_min_timestamp> = max_timestamp):
break
local_max_timestamp = local_min_timestamp + date_increment
if (local_max_timestamp> max_timestamp):
local_max_timestamp = max_timestamp
print timestamptodate (local_min_timestamp), '-', timestamptodate (local_max_timestamp)
vk_json = json.loads (get_vk (location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp))
for local_i in vk_json ['response']:
if type (local_i) is int:
continue
file_inst.write ('
')
file_inst.write (' <img src='+local_i['src_big']+'>
')
file_inst.write (timestamptodate (int (local_i ['created'])) + '
')
file_inst.write ('https://vk.com/id'+str (local_i [' owner_id ']) +'
')
file_inst.write ('
')
local_min_timestamp = local_max_timestamp
file_inst.write (' </html> ')
file_inst.close ()
And of course, the function calls themselves:
parse_instagram (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, instagram_access_token)
parse_vk (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment)
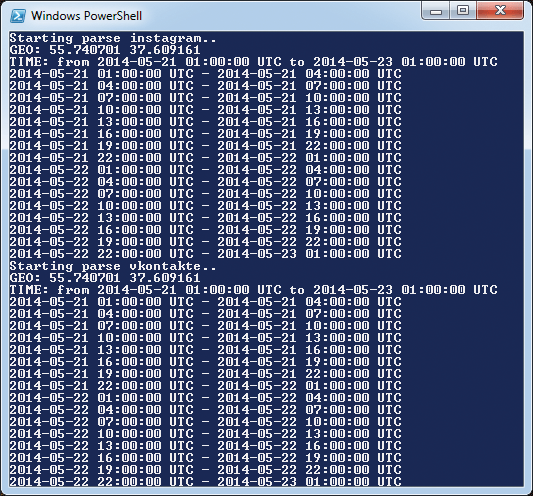
The result of our script in the console

One of the results of parsing Instagram

Result of parsing "Contact"
Baptism of fire
The script is ready, it remains only to test it in action. And then an idea occurred to me. Those who were at PHD'14 probably remembered the very nice promos from Mail.Ru. Well, let's try to catch up - find them and get to know each other.
Actually, what do we know about PHD14:
Venue - Digital October - 55.740701.37.609161;
Date: May 21-22, 2014 - 1400619600-1400792400.
We get the following data set:
location_latitude = '55 .740701 '
location_longitude = '37 .609161 '
distance = '100'
min_timestamp = 1400619600
max_timestamp = 1400792400
date_increment = 60 * 60 * 3 # every 3 hours
instagram_access_token = [Access Token]
Useful Tips
If as a result of the script work there are too few photos, you can try changing the `date_increment` variable, since it is it that is responsible for the time intervals over which the photos are collected. If the place is popular, then the intervals should be frequent (reduce the `date_increment)`, but if the place is blank and photos are published once a month, then collecting photos at intervals of an hour does not make sense (increase the `date_increment`).
Run the script and go to analyze the results. Yeah, one of the girls posted a picture taken in the mirror in the toilet, with reference to the coordinates! Naturally, the API did not forgive such an error, and soon the pages of all the other promotions were found. As it turned out, two of them are twins") .
.

The same photo of a promo girl with PHD'14 taken in the toilet
Instructive example
As a second example, I want to recall one of the tasks from the CTF finals at PHD'14. Actually, it was after him that I became interested in this topic. Its essence was as follows.
There is an evil hacker who developed a certain malware. We are given a set of coordinates and the corresponding timestamps from which he went online. You need to get a name and a picture of this hacker. The coordinates were as follows:
55.7736147,37.6567926 30 Apr 2014 19:15 MSK;
55.4968379,40.7731697 30 Apr 2014 23:00 MSK;
55.5625259,42.0185773 1 May 2014 00:28 MSK;
55.5399274,42.1926434 1 May 2014 00:46 MSK;
55.5099579,47.4776127 1 May 2014 05:44 MSK;
55.6866654,47.9438484 1 May 2014 06:20 MSK;
55.8419686,48.5611181 1 May 2014 07:10 MSK
First of all, of course, we looked at what places correspond to these coordinates. As it turned out, these are Russian Railways stations, with the first coordinate being the Kazan railway station (Moscow), and the last - Zeleny Dol (Zelenodolsk). The rest are stations between Moscow and Zelenodolsk. It turns out that he went online from the train. At the time of departure, the desired train was found. As it turned out, the train's arrival station is Kazan. And then the main question arose: where to look for the name and photo. The logic was as follows: since you need to find a photo, it is quite reasonable to assume that you need to look for it somewhere on social networks. The main goals were chosen VKontakte, Facebook, Instagram and Twitter. In addition to the Russian teams, foreigners participated in the competitions, so we felt that the organizers would hardly have chosen VKontakte. It was decided to start with Instagram.
We did not have any scripts to search for photos by coordinates and time, and we had to use public services that could do this. As it turned out, there are quite a few of them and they provide a rather meager interface. After hundreds of photos viewed at each station, the train was finally found needed.
As a result, to find the train and the missing stations, as well as the logic of further search, it took no more than an hour. But finding the right photo is a lot of time. This once again emphasizes how important it is to have the right and convenient programs in your arsenal.
WWW
You can find the source code of the script in my Bitbucket repository.
conclusions
The article came to an end, and it was time to draw a conclusion. But the conclusion is simple: upload photos with geo-referencing need to be deliberate. Competitive intelligence agents are ready to cling to any opportunity to get new information, and the social network APIs can help them very well in this. When I wrote this article, I explored several other services, including Twitter, Facebook and LinkedIn, whether there is such functionality. Only Twitter provided positive results, which undoubtedly pleases. But Facebook and LinkedIn upset, although not everything is lost and, perhaps, in the future they will expand their APIs. In general, be more careful when posting your photos with geo-referencing - suddenly, someone else will find them.

First published in the Hacker magazine from 02/2015.
Posted by Arkady Litvinenko (@Betepk)
https://m.habrahabr.ru/company/xakep/blog/254129/
It's no secret that modern social networks are huge databases containing a lot of interesting information about the privacy of their users. You won’t get much data through the web-face, but each network has its own API ... So let's see how this can be used to find users and collect information about them.
There is a discipline in American intelligence such as OSINT (Open source intelligence), which is responsible for the search, collection and selection of information from public sources. One of the largest providers of publicly available information includes social networks. Indeed, almost every one of us has an account (and someone has more than one) in one or more social networks. Here we share our news, personal photos, tastes (for example, like something or joining a group), the circle of our acquaintances. And we do this of our own free will and practically do not think about the possible consequences. The pages of the magazine have repeatedly considered how to extract interesting data from social networks using various tricks. Usually, for this it was necessary to manually perform some kind of manipulation. But for successful reconnaissance, it is more logical to use special utilities. There are several open source utilities that allow you to pull information about users from social networks.
Creepy
One of the most popular is Creepy. It is designed to collect geolocation information about the user based on data from his Twitter, Instagram, Google+ and Flickr accounts. The advantages of this tool, which is standardly included in Kali Linux, include an intuitive interface, a very convenient process of obtaining tokens for using API services, as well as displaying the results found by labels on the map (which, in turn, allows you to track all user movements). The disadvantages I would include a rather weak functionality. Tulsa knows how to collect geotags for these services and display them on a Google map, shows who and how many times the user retweeted, considers statistics on the devices from which tweets were written, as well as the time they were published. But due to the fact that this is an open source tool, its functionality can always be expanded by yourself.
We will not consider how to use the program - everything is perfectly shown in the official video, after watching which there should not be any questions about working with the tool.
fbStalker
Two other tools that are less known, but have strong functionality and deserve your attention are fbStalker and geoStalker.
fbStalker is designed to collect user information based on its Facebook profile. Allows you to get the following data:
videos, photos, user posts;
who and how many times liked his posts;
geolocation of photos;
statistics of comments on his posts and photos;
the time that he usually visits online.
For this tool to work, you will need Google Chrome, ChromeDriver, which is installed as follows:
wget [DLMURL] https://goo.gl/Kvh33W [/ DLMURL]
unzip chromedriver_linux32_23.0.1240.0.zip
cp chromedriver / usr / bin / chromedriver
chmod 777 / usr / bin / chromedriver
In addition, you will need installed Python 2.7, as well as pip to install the following packages:
pip install pytz
pip install tzlocal
pip install termcolor
pip install selenium
pip install requests --upgrade
pip install beautifulsoup4
And finally, you need a library for parsing GraphML files:
git clone [DLMURL] https://github.com/hadim/pygraphml.git [/ DLMURL]
cd pygraphml
python2.7 setup.py install
After that, it will be possible to fix the `fbstalker.py`, indicating there your soap, password, username, and start the search. Using the tool is quite simple:
python fbstalker.py -user [username of interest]
geoStalker
geoStalker is much more interesting. He collects information on the coordinates that you gave him. For example:
local Wi-Fi-points based on the base `wigle.net` (in particular, their` essid`, `bssid`,` geo`);
Checks from Foursquare;
Instagram and Flickr accounts from which photos were posted with reference to these coordinates;
all tweets made in the area.
For the tool to work, as in the previous case, you will need Chrome & ChromeDriver, Python 2.7, pip (to install the following packages: google, python-instagram, pygoogle, geopy, lxml, oauth2, python-linkedin, pygeocoder, selenium, termcolor, pysqlite , TwitterSearch, foursquare), as well as pygraphml and gdata:
git clone [DLMURL] https://github.com/hadim/pygraphml.git [/ DLMURL]
cd pygraphml
python2.7 setup.py install
wget https://gdata-python-client.googlecode. ... .18.tar.gz
tar xvfz gdata-2.0.18.tar.gz
cd gdata-2.0.18
python2.7 setup.py install
After that, edit `geostalker.py`, filling out all the necessary API keys and access tokens (if for any social network this data is not specified, then it simply will not participate in the search). After that, run the tool with the command `sudo python2.7 geostalker.py` and specify the address or coordinates. As a result, all data is collected and placed on a Google map, and also saved in an HTML file.
Move on to action
Before that, it was about ready-made tools. In most cases, their functionality will be lacking and you will either have to modify them or write your own tools - all popular social networks provide their APIs. Usually they appear as a separate subdomain to which we send GET requests, and in response we get XML / JSON responses. For example, for "Instagram" it is `api.instagram.com`, for" Contact "it is` api.vk.com`. Of course, most of these APIs have their own libraries of functions for working with them, but we want to understand how it works, and to make the script heavier with unnecessary external libraries due to one or two functions not comme il faut. So, let's take and write our own tool that would allow us to search for photos from VK and Instagram based on the given coordinates and time interval.
Using the documentation for API VK and Instagram, we make requests for a list of photos by geographical information and time.
Instagram API Request:
url = "https://api.instagram.com/v1/media/search?"
+ "lat =" + location_latitude
+ "& lng =" + location_longitude
+ "& distance =" + distance
+ "& min_timestamp =" + timestamp
+ "& max_timestamp =" + (timestamp + date_increment)
+ "& access_token =" + access_token
Vkontakte API Request:
url = "https://api.vk.com/method/photos.search?"
+ "lat =" + location_latitude
+ "& long =" + location_longitude
+ "& count =" + 100
+ "& radius =" + distance
+ "& start_time =" + timestamp
+ "& end_time =" + (timestamp + date_increment)
The variables used here are:
location_latitude - geographical latitude;
location_longitude - geographical longitude;
distance - search radius;
timestamp - initial border of the time interval;
date_increment - the number of seconds from the start to the end of the time interval;
access_token - developer token.
As it turned out, access to Instagram requires access_token. It’s easy to get it, but you’ll have to get a little confused (see sidebar). Contact is more loyal to strangers, which is very good for us.
Getting Instagram Access Token
To get started, register on instagram. After registration, go to the following link:
instagram.com/developer/clients/manage
Click ** Register a New Client **. Enter the phone number, wait for the message and enter the code. In the window for creating a new client that opens, we need to fill in the important fields for us as follows:
OAuth redirect_uri: localhost
Disable implicit OAuth: checkmark must be unchecked
The remaining fields are filled arbitrarily. Once everything is full, create a new client. Now you need to get the token. To do this, enter the following URL in the address bar of the browser:
[DLMURL] https://instagram.com/oauth/authorize/?client_id= [/ DLMURL] [CLIENT_ID] & redirect_uri = http: // localhost / & response_type = token
where instead of [CLIENT_ID] specify the Client ID of the client you created. After that, follow the link, and if you did everything correctly, then you will be forwarded to localhost and Access Token will be written in the address bar.
http: // localhost / # access_token = [Access Token]
You can read more about this method of obtaining a token at the following link: jelled.com/instagram/access-token.
Automate the process
So, we learned how to make the necessary queries, but manually parsing the server response (in the form of JSON / XML) is not the coolest task. It is much more convenient to make a small script that will do this for us. We will use again Python 2.7. The logic is as follows: we are looking for all the photos that fall in a given radius relative to the given coordinates in a given period of time. But consider one very important point - a limited number of photos are displayed. Therefore, for a large period of time, you will have to make several requests with intermediate time intervals (just date_increment). Also take into account the accuracy of the coordinates and do not specify a radius of several meters. And do not forget that time must be specified in timestamp.
We begin to code. First, we’ll connect all the libraries we need:
import httplib
import urllib
import json
import datetime
We write functions for receiving data from the API via HTTPS. Using the passed arguments to the function, we compose a GET request and return the server response as a string.
def get_instagram (latitude, longitude, distance, min_timestamp, max_timestamp, access_token):
get_request = '/ v1 / media / search? lat =' + latitude
get_request + = '& lng =' + longitude
get_request + = '& distance =' + distance
get_request + = '& min_timestamp =' + str (min_timestamp)
get_request + = '& max_timestamp =' + str (max_timestamp)
get_request + = '& access_token =' + access_token
local_connect = httplib.HTTPSConnection ('api.instagram.com', 443)
local_connect.request ('GET', get_request)
return local_connect.getresponse (). read ()
def get_vk (latitude, longitude, distance, min_timestamp, max_timestamp):
get_request = '/method/photos.search?lat=' + location_latitude
get_request + = '& long =' + location_longitude
get_request + = '& count = 100'
get_request + = '& radius =' + distance
get_request + = '& start_time =' + str (min_timestamp)
get_request + = '& end_time =' + str (max_timestamp)
local_connect = httplib.HTTPSConnection ('api.vk.com', 443)
local_connect.request ('GET', get_request)
return local_connect.getresponse (). read ()
We also find a small function to convert timestamp to human view:
def timestamptodate (timestamp):
return datetime.datetime.fromtimestamp (timestamp) .strftime ('% Y-% m-% d% H:% M:% S') + 'UTC'
Now we write the main logic for image search, after dividing the time interval into parts, we save the results in an HTML file. The function looks cumbersome, but the main difficulty in it is dividing the time interval into blocks. The rest is just parsing JSON and storing the necessary data in HTML.
def parse_instagram (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, access_token):
print 'Starting parse instagram ..'
print 'GEO:', location_latitude, location_longitude
print 'TIME: from', timestamptodate (min_timestamp), 'to', timestamptodate (max_timestamp)
file_inst = open ('instagram _' + location_latitude + location_longitude + '. html', 'w')
file_inst.write (' <html> ')
local_min_timestamp = min_timestamp
while (1):
if (local_min_timestamp> = max_timestamp):
break
local_max_timestamp = local_min_timestamp + date_increment
if (local_max_timestamp> max_timestamp):
local_max_timestamp = max_timestamp
print timestamptodate (local_min_timestamp), '-', timestamptodate (local_max_timestamp)
local_buffer = get_instagram (location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp, access_token)
instagram_json = json.loads (local_buffer)
for local_i in instagram_json ['data']:
file_inst.write ('
')
file_inst.write (' <img src='+local_i['images']['standard_resolution']['url']+'>
')
file_inst.write (timestamptodate (int (local_i ['created_time']))) + '
')
file_inst.write (local_i ['link'] + '
')
file_inst.write ('
')
local_min_timestamp = local_max_timestamp
file_inst.write (' </html> ')
file_inst.close ()
The HTML format was chosen for a reason. It allows us not to save pictures separately, but only indicate links to them. When the page starts, the results in the image browser are automatically loaded.
We are writing exactly the same function for “Contact”.
def parse_vk (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment):
print 'Starting parse vkontakte ..'
print 'GEO:', location_latitude, location_longitude
print 'TIME: from', timestamptodate (min_timestamp), 'to', timestamptodate (max_timestamp)
file_inst = open ('vk _' + location_latitude + location_longitude + '. html', 'w')
file_inst.write (' <html> ')
local_min_timestamp = min_timestamp
while (1):
if (local_min_timestamp> = max_timestamp):
break
local_max_timestamp = local_min_timestamp + date_increment
if (local_max_timestamp> max_timestamp):
local_max_timestamp = max_timestamp
print timestamptodate (local_min_timestamp), '-', timestamptodate (local_max_timestamp)
vk_json = json.loads (get_vk (location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp))
for local_i in vk_json ['response']:
if type (local_i) is int:
continue
file_inst.write ('
')
file_inst.write (' <img src='+local_i['src_big']+'>
')
file_inst.write (timestamptodate (int (local_i ['created'])) + '
')
file_inst.write ('https://vk.com/id'+str (local_i [' owner_id ']) +'
')
file_inst.write ('
')
local_min_timestamp = local_max_timestamp
file_inst.write (' </html> ')
file_inst.close ()
And of course, the function calls themselves:
parse_instagram (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, instagram_access_token)
parse_vk (location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment)
The result of our script in the console
One of the results of parsing Instagram
Result of parsing "Contact"
Baptism of fire
The script is ready, it remains only to test it in action. And then an idea occurred to me. Those who were at PHD'14 probably remembered the very nice promos from Mail.Ru. Well, let's try to catch up - find them and get to know each other.
Actually, what do we know about PHD14:
Venue - Digital October - 55.740701.37.609161;
Date: May 21-22, 2014 - 1400619600-1400792400.
We get the following data set:
location_latitude = '55 .740701 '
location_longitude = '37 .609161 '
distance = '100'
min_timestamp = 1400619600
max_timestamp = 1400792400
date_increment = 60 * 60 * 3 # every 3 hours
instagram_access_token = [Access Token]
Useful Tips
If as a result of the script work there are too few photos, you can try changing the `date_increment` variable, since it is it that is responsible for the time intervals over which the photos are collected. If the place is popular, then the intervals should be frequent (reduce the `date_increment)`, but if the place is blank and photos are published once a month, then collecting photos at intervals of an hour does not make sense (increase the `date_increment`).
Run the script and go to analyze the results. Yeah, one of the girls posted a picture taken in the mirror in the toilet, with reference to the coordinates! Naturally, the API did not forgive such an error, and soon the pages of all the other promotions were found. As it turned out, two of them are twins
.
The same photo of a promo girl with PHD'14 taken in the toilet
Instructive example
As a second example, I want to recall one of the tasks from the CTF finals at PHD'14. Actually, it was after him that I became interested in this topic. Its essence was as follows.
There is an evil hacker who developed a certain malware. We are given a set of coordinates and the corresponding timestamps from which he went online. You need to get a name and a picture of this hacker. The coordinates were as follows:
55.7736147,37.6567926 30 Apr 2014 19:15 MSK;
55.4968379,40.7731697 30 Apr 2014 23:00 MSK;
55.5625259,42.0185773 1 May 2014 00:28 MSK;
55.5399274,42.1926434 1 May 2014 00:46 MSK;
55.5099579,47.4776127 1 May 2014 05:44 MSK;
55.6866654,47.9438484 1 May 2014 06:20 MSK;
55.8419686,48.5611181 1 May 2014 07:10 MSK
First of all, of course, we looked at what places correspond to these coordinates. As it turned out, these are Russian Railways stations, with the first coordinate being the Kazan railway station (Moscow), and the last - Zeleny Dol (Zelenodolsk). The rest are stations between Moscow and Zelenodolsk. It turns out that he went online from the train. At the time of departure, the desired train was found. As it turned out, the train's arrival station is Kazan. And then the main question arose: where to look for the name and photo. The logic was as follows: since you need to find a photo, it is quite reasonable to assume that you need to look for it somewhere on social networks. The main goals were chosen VKontakte, Facebook, Instagram and Twitter. In addition to the Russian teams, foreigners participated in the competitions, so we felt that the organizers would hardly have chosen VKontakte. It was decided to start with Instagram.
We did not have any scripts to search for photos by coordinates and time, and we had to use public services that could do this. As it turned out, there are quite a few of them and they provide a rather meager interface. After hundreds of photos viewed at each station, the train was finally found needed.
As a result, to find the train and the missing stations, as well as the logic of further search, it took no more than an hour. But finding the right photo is a lot of time. This once again emphasizes how important it is to have the right and convenient programs in your arsenal.
WWW
You can find the source code of the script in my Bitbucket repository.
conclusions
The article came to an end, and it was time to draw a conclusion. But the conclusion is simple: upload photos with geo-referencing need to be deliberate. Competitive intelligence agents are ready to cling to any opportunity to get new information, and the social network APIs can help them very well in this. When I wrote this article, I explored several other services, including Twitter, Facebook and LinkedIn, whether there is such functionality. Only Twitter provided positive results, which undoubtedly pleases. But Facebook and LinkedIn upset, although not everything is lost and, perhaps, in the future they will expand their APIs. In general, be more careful when posting your photos with geo-referencing - suddenly, someone else will find them.
First published in the Hacker magazine from 02/2015.
Posted by Arkady Litvinenko (@Betep
k) https://m.habrahabr.ru/company/xakep/blog/254129/
 Original message
Original message
Я тебя по сетям вычислю: используем API крупнейших соцсетей в своих корыстных целях.
Ни для кого не секрет, что современные социальные сети представляют собой огромные БД, содержащие много интересной информации о частной жизни своих пользователей. Через веб-морду особо много данных не вытянешь, но ведь у каждой сети есть свой API… Так давай же посмотрим, как этим можно воспользоваться для поиска пользователей и сбора информации о них.
Есть в американской разведке такая дисциплина, как OSINT (Open source intelligence), которая отвечает за поиск, сбор и выбор информации из общедоступных источников. К одному из крупнейших поставщиков общедоступной информации можно отнести социальные сети. Ведь практически у каждого из нас есть учетка (а у кого-то и не одна) в одной или нескольких соцсетях. Тут мы делимся своими новостями, личными фотографиями, вкусами (например, лайкая что-то или вступая в какую-либо группу), кругом своих знакомств. Причем делаем это по своей доброй воле и практически совершенно не задумываемся о возможных последствиях. На страницах журнала уже не раз рассматривали, как можно с помощью различных уловок вытаскивать из соцсетей интересные данные. Обычно для этого нужно было вручную совершить какие-то манипуляции. Но для успешной разведки логичнее воспользоваться специальными утилитами. Существует несколько open source утилит, позволяющих вытаскивать информацию о пользователях из соцсетей.
Creepy
Одна из наиболее популярных — Creepy. Она предназначена для сбора геолокационной информации о пользователе на основе данных из его аккаунтов Twitter, Instagram, Google+ и Flickr. К достоинствам этого инструмента, который штатно входит в Kali Linux, стоит отнести понятный интерфейс, очень удобный процесс получения токенов для использования API сервисов, а также отображение найденных результатов метками на карте (что, в свою очередь, позволяет проследить за всеми перемещениями пользователя). К недостаткам я бы отнес слабоватый функционал. Тулза умеет собирать геотеги по перечисленным сервисам и выводить их на Google-карте, показывает, кого и сколько раз ретвитил пользователь, считает статистику по устройствам, с которых писались твиты, а также по времени их публикации. Но за счет того, что это open source инструмент, его функционал всегда можно расширить самому.
Рассматривать, как использовать программу, не будем — все отлично показано в официальном видео, после просмотра которого не должно остаться никаких вопросов по поводу работы с инструментом.
fbStalker
Еще два инструмента, которые менее известны, но обладают сильным функционалом и заслуживают твоего внимания, — fbStalker и geoStalker.
fbStalker предназначен для сбора информации о пользователе на основе его Facebook-профиля. Позволяет выцепить следующие данные:
видео, фото, посты пользователя;
кто и сколько раз лайкнул его записи;
геопривязки фоток;
статистика комментариев к его записям и фотографиям;
время, в которое он обычно бывает в онлайне.
Для работы данного инструмента тебе понадобится Google Chrome, ChromeDriver, который устанавливается следующим образом:
wget [DLMURL]https://goo.gl/Kvh33W[/DLMURL]
unzip chromedriver_linux32_23.0.1240.0.zip
cp chromedriver /usr/bin/chromedriver
chmod 777 /usr/bin/chromedriver
Помимо этого, понадобится установленный Python 2.7, а также pip для установки следующих пакетов:
pip install pytz
pip install tzlocal
pip install termcolor
pip install selenium
pip install requests --upgrade
pip install beautifulsoup4
И наконец, понадобится библиотека для парсинга GraphML-файлов:
git clone [DLMURL]https://github.com/hadim/pygraphml.git[/DLMURL]
cd pygraphml
python2.7 setup.py install
После этого можно будет поправить `fbstalker.py`, указав там свое мыло, пароль, имя пользователя, и приступать к поиску. Пользоваться тулзой достаточно просто:
python fbstalker.py -user [имя интересующего пользователя]
geoStalker
geoStalker значительно интереснее. Он собирает информацию по координатам, которые ты ему передал. Например:
местные Wi-Fi-точки на основе базы `wigle.net` (в частности, их `essid`, `bssid`, `geo`);
чекины из Foursquare;
Instagram- и Flickr-аккаунты, с которых постились фотки с привязкой к этим координатам;
все твиты, сделанные в этом районе.
Для работы инструмента, как и в предыдущем случае, понадобится Chrome & ChromeDriver, Python 2.7, pip (для установки следующих пакетов: google, python-instagram, pygoogle, geopy, lxml, oauth2, python-linkedin, pygeocoder, selenium, termcolor, pysqlite, TwitterSearch, foursquare), а также pygraphml и gdata:
git clone [DLMURL]https://github.com/hadim/pygraphml.git[/DLMURL]
cd pygraphml
python2.7 setup.py install
wget https://gdata-python-client.googlecode. ... .18.tar.gz
tar xvfz gdata-2.0.18.tar.gz
cd gdata-2.0.18
python2.7 setup.py install
После этого редактируем `geostalker.py`, заполняя все необходимые API-ключи и access-токены (если для какой-либо соцсети эти данные не будут указаны, то она просто не будет участвовать в поиске). После чего запускаем инструмент командой `sudo python2.7 geostalker.py` и указываем адрес или координаты. В результате все данные собираются и размещаются на Google-карте, а также сохраняются в HTML-файл.
Переходим к действиям
До этого речь шла о готовых инструментах. В большинстве случаев их функционала будет не хватать и придется либо их дорабатывать, либо писать свои тулзы — все популярные соцсети предоставляют свои API. Обычно они предстают в виде отдельного поддомена, на который мы шлем GET-запросы, а в ответ получаем XML/JSON-ответы. Например, для «Инстаграма» это `api.instagram.com`, для «Контакта» — `api.vk.com`. Конечно, у большинства таких API есть свои библиотеки функций для работы с ними, но мы ведь хотим разобраться, как это работает, да и утяжелять скрипт лишними внешними библиотеками из-за одной-двух функций не комильфо. Итак, давай возьмем и напишем собственный инструмент, который бы позволял искать фотографии из ВК и «Инстаграма» по заданным координатам и промежутку времени.
Используя документацию к API VK и Instagram, составляем запросы для получения списка фотографий по географической информации и времени.
Instagram API Request:
url = "https://api.instagram.com/v1/media/search?"
+ "lat=" + location_latitude
+ "&lng=" + location_longitude
+ "&distance=" + distance
+ "&min_timestamp=" + timestamp
+ "&max_timestamp=" + (timestamp + date_increment)
+ "&access_token=" + access_token
Vkontakte API Request:
url = "https://api.vk.com/method/photos.search?"
+ "lat=" + location_latitude
+ "&long=" + location_longitude
+ "&count=" + 100
+ "&radius=" + distance
+ "&start_time=" + timestamp
+ "&end_time=" + (timestamp + date_increment)
Здесь используемые переменные:
location_latitude — географическая широта;
location_longitude — географическая долгота;
distance — радиус поиска;
timestamp — начальная граница интервала времени;
date_increment — количество секунд от начальной до конечной границы интервала времени;
access_token — токен разработчика.
Как выяснилось, для доступа к Instagram API требуется access_token. Получить его несложно, но придется немного заморочиться (смотри врезку). Контакт же более лояльно относится к незнакомцам, что очень хорошо для нас.
Получение Instagram Access Token
Для начала регистрируешься в инстаграме. После регистрации переходишь по следующей ссылке:
instagram.com/developer/clients/manage
Жмешь **Register a New Client**. Вводишь номер телефона, ждешь эсэмэску и вводишь код. В открывшемся окне создания нового клиента важные для нас поля нужно заполнить следующим образом:
OAuth redirect_uri: localhost
Disable implicit OAuth: галочка должна быть снята
Остальные поля заполняются произвольно. Как только все заполнил, создавай нового клиента. Теперь нужно получить токен. Для этого впиши в адресную строку браузера следующий URL:
[DLMURL]https://instagram.com/oauth/authorize/?client_id=[/DLMURL][CLIENT_ID]&redirect_uri=https://localhost/&response_type=token
где вместо [CLIENT_ID] укажи Client ID созданного тобой клиента. После этого делай переход по получившейся ссылке, и если ты сделал все правильно, то тебя переадресует на localhost и в адресной строке как раз будет написан Access Token.
https://localhost/#access_token=[Access Token]
Более подробно про этот метод получения токена можешь почитать по следующей ссылке: jelled.com/instagram/access-token.
Автоматизируем процесс
Итак, мы научились составлять нужные запросы, но вручную разбирать ответ сервера (в виде JSON/XML) — не самое крутое занятие. Гораздо удобнее сделать небольшой скриптик, который будет делать это за нас. Использовать мы будем опять же Python 2.7. Логика следующая: мы ищем все фото, которые попадают в заданный радиус относительно заданных координат в заданный промежуток времени. Но учитывай один очень важный момент — выводится ограниченное количество фотографий. Поэтому для большого промежутка времени придется делать несколько запросов с промежуточными интервалами времени (как раз date_increment). Также учитывай погрешность координат и не указывай радиус в несколько метров. И не забывай, что время нужно указывать в timestamp.
Начинаем кодить. Для начала подключим все необходимые нам библиотеки:
import httplib
import urllib
import json
import datetime
Пишем функции для получения данных с API через HTTPS. С помощью переданных аргументов функции мы составляем GET-запрос и возвращаем ответ сервера строкой.
def get_instagram(latitude, longitude, distance, min_timestamp, max_timestamp, access_token):
get_request = '/v1/media/search?lat=' + latitude
get_request+= '&lng=' + longitude
get_request += '&distance=' + distance
get_request += '&min_timestamp=' + str(min_timestamp)
get_request += '&max_timestamp=' + str(max_timestamp)
get_request += '&access_token=' + access_token
local_connect = httplib.HTTPSConnection('api.instagram.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
def get_vk(latitude, longitude, distance, min_timestamp, max_timestamp):
get_request = '/method/photos.search?lat=' + location_latitude
get_request+= '&long=' + location_longitude
get_request+= '&count=100'
get_request+= '&radius=' + distance
get_request+= '&start_time=' + str(min_timestamp)
get_request+= '&end_time=' + str(max_timestamp)
local_connect = httplib.HTTPSConnection('api.vk.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
Еще находим небольшую функцию конвертации timestamp в человеческий вид:
def timestamptodate(timestamp):
return datetime.datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d %H:%M:%S')+' UTC'
Теперь пишем основную логику поиска картинок, предварительно разбив временной отрезок на части, результаты сохраняем в HTML-файл. Функция выглядит громоздко, но основную сложность в ней составляет разбиение временного интервала на блоки. В остальном это обычный парсинг JSON и сохранение нужных данных в HTML.
def parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, access_token):
print 'Starting parse instagram..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('instagram_'+location_latitude+location_longitude+'.html','w')
file_inst.write('<html>')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
local_buffer = get_instagram(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp, access_token)
instagram_json = json.loads(local_buffer)
for local_i in instagram_json['data']:
file_inst.write('<br>')
file_inst.write('<img src='+local_i['images']['standard_resolution']['url']+'><br>')
file_inst.write(timestamptodate(int(local_i['created_time']))+'<br>')
file_inst.write(local_i['link']+'<br>')
file_inst.write('<br>')
local_min_timestamp = local_max_timestamp
file_inst.write('</html>')
file_inst.close()
HTML-формат выбран не просто так. Он позволяет нам не сохранять картинки отдельно, а лишь указать ссылки на них. При запуске страницы результаты в браузере картинки автоматически подгрузятся.
Пишем точно такую же функцию для «Контакта».
def parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment):
print 'Starting parse vkontakte..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('vk_'+location_latitude+location_longitude+'.html','w')
file_inst.write('<html>')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
vk_json = json.loads(get_vk(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp))
for local_i in vk_json['response']:
if type(local_i) is int:
continue
file_inst.write('<br>')
file_inst.write('<img src='+local_i['src_big']+'><br>')
file_inst.write(timestamptodate(int(local_i['created']))+'<br>')
file_inst.write('https://vk.com/id'+str(local_i['owner_id'])+'<br>')
file_inst.write('<br>')
local_min_timestamp = local_max_timestamp
file_inst.write('</html>')
file_inst.close()
И конечно же, сами вызовы функций:
parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, instagram_access_token)
parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment)
Результат работы нашего скрипта в консоли
Один из результатов парсинга Инстаграма
Результат парсинга «Контакта»
Боевое крещение
Скрипт готов, осталось его только опробовать в действии. И тут мне пришла в голову одна идея. Те, кто был на PHD’14, наверняка запомнили очень симпатичных промодевочек от Mail.Ru. Что ж, давай попробуем наверстать упущенное — найти их и познакомиться.
Собственно, что мы знаем об PHD14:
место проведения — Digital October — 55.740701,37.609161;
дата проведения — 21–22 мая 2014 года — 1400619600–1400792400.
Получаем следующий набор данных:
location_latitude = '55.740701'
location_longitude = '37.609161'
distance = '100'
min_timestamp = 1400619600
max_timestamp = 1400792400
date_increment = 60*60*3 # every 3 hours
instagram_access_token = [Access Token]
Полезные советы
Если в результате работы скрипта фотографий будет слишком мало, можешь пробовать изменять переменную `date_increment`, поскольку именно она отвечает за интервалы времени, по которым собираются фотографии. Если место популярное, то и интервалы должны быть частыми (уменьшаем `date_increment)`, если же место глухое и фотографии публикуют раз в месяц, то и сбор фотографий интервалами в час не имеет смысла (увеличиваем `date_increment`).
Запускаем скрипт и идем разбирать полученные результаты. Ага, одна из девочек выложила фотку, сделанную в зеркале в туалете, с привязкой по координатам! Естественно, API не простил такой ошибки, и вскоре были найдены странички всех остальных промодевочек. Как оказалось, две из них близняшки.
Та самая фотография промо-девочки с PHD’14, сделанная в туалете
Поучительный пример
В качестве второго примера хочется вспомнить одно из заданий с финала CTF на PHD’14. Собственно, именно после него я заинтересовался данной темой. Суть его заключалась в следующем.
Есть злой хацкер, который разработал некую малварь. Нам дан набор координат и соответствующих им временных меток, из которых он выходил в интернет. Нужно добыть имя и фотку это хацкера. Координаты были следующие:
55.7736147,37.6567926 30 Apr 2014 19:15 MSK;
55.4968379,40.7731697 30 Apr 2014 23:00 MSK;
55.5625259,42.0185773 1 May 2014 00:28 MSK;
55.5399274,42.1926434 1 May 2014 00:46 MSK;
55.5099579,47.4776127 1 May 2014 05:44 MSK;
55.6866654,47.9438484 1 May 2014 06:20 MSK;
55.8419686,48.5611181 1 May 2014 07:10 MSK
Первым делом мы, естественно, посмотрели, каким местам соответствуют эти координаты. Как оказалось, это станции РЖД, причем первая координата — это Казанский вокзал (Москва), а последняя — Зеленый Дол (Зеленодольск). Остальные — это станции между Москвой и Зеленодольском. Получается, что он выходил в интернет из поезда. По времени отправления был найден нужный поезд. Как оказалось, станцией прибытия поезда является Казань. И тут встал главный вопрос: где искать имя и фотку. Логика заключалась в следующем: поскольку требуется найти фотку, то вполне разумно предположить, что искать ее нужно где-то в социальных сетях. Основными целями были выбраны «ВКонтакте», «Фейсбук», «Инстаграм» и «Твиттер». В соревнованиях помимо русских команд участвовали иностранцы, поэтому мы посчитали, что организаторы вряд ли бы выбрали «ВКонтакте». Решено было начать с «Инстаграма».
Никакими скриптами для поиска фотографий по координатам и времени мы тогда не обладали, и пришлось использовать публичные сервисы, умевшие это делать. Как выяснилось, их довольно мало и они предоставляют довольно скудный интерфейс. Спустя сотни просмотренных фотографий на каждой станции движения поезда наконец была найдена нужная.
В итоге, чтобы найти поезд и недостающие станции, а также логику дальнейшего поиска, понадобилось не больше часа. А вот на поиск нужной фотографии — очень много времени. Это еще раз подчеркивает, насколько важно иметь правильные и удобные программы в своем арсенале.
WWW
Исходный код рассмотренного скрипта ты можешь найти в моем Bitbucket-репозитории
Выводы
Статья подошла к завершению, и настало время делать вывод. А вывод простой: заливать фотографии с геопривязкой нужно обдуманно. Конкурентные разведчики готовы зацепиться за любую возможность получить новую информацию, и API социальных сетей им в этом могут очень неплохо помочь. Когда писал эту статью, я изучил еще несколько сервисов, в том числе Twitter, Facebook и LinkedIn, — есть ли подобный функционал. Положительные результаты дал только «Твиттер», что, несомненно, радует. А вот Facebook и LinkedIn огорчили, хотя еще не все потеряно и, возможно, в будущем они расширят свои API. В общем, будь внимательнее, выкладывая свои фото с геопривязкой, — вдруг их найдет кто-нибудь не тот.
Впервые опубликовано в журнале «Хакер» от 02/2015.
Автор: Аркадий Литвиненко (@Betepk)
https://m.habrahabr.ru/company/xakep/blog/254129/
Ни для кого не секрет, что современные социальные сети представляют собой огромные БД, содержащие много интересной информации о частной жизни своих пользователей. Через веб-морду особо много данных не вытянешь, но ведь у каждой сети есть свой API… Так давай же посмотрим, как этим можно воспользоваться для поиска пользователей и сбора информации о них.
Есть в американской разведке такая дисциплина, как OSINT (Open source intelligence), которая отвечает за поиск, сбор и выбор информации из общедоступных источников. К одному из крупнейших поставщиков общедоступной информации можно отнести социальные сети. Ведь практически у каждого из нас есть учетка (а у кого-то и не одна) в одной или нескольких соцсетях. Тут мы делимся своими новостями, личными фотографиями, вкусами (например, лайкая что-то или вступая в какую-либо группу), кругом своих знакомств. Причем делаем это по своей доброй воле и практически совершенно не задумываемся о возможных последствиях. На страницах журнала уже не раз рассматривали, как можно с помощью различных уловок вытаскивать из соцсетей интересные данные. Обычно для этого нужно было вручную совершить какие-то манипуляции. Но для успешной разведки логичнее воспользоваться специальными утилитами. Существует несколько open source утилит, позволяющих вытаскивать информацию о пользователях из соцсетей.
Creepy
Одна из наиболее популярных — Creepy. Она предназначена для сбора геолокационной информации о пользователе на основе данных из его аккаунтов Twitter, Instagram, Google+ и Flickr. К достоинствам этого инструмента, который штатно входит в Kali Linux, стоит отнести понятный интерфейс, очень удобный процесс получения токенов для использования API сервисов, а также отображение найденных результатов метками на карте (что, в свою очередь, позволяет проследить за всеми перемещениями пользователя). К недостаткам я бы отнес слабоватый функционал. Тулза умеет собирать геотеги по перечисленным сервисам и выводить их на Google-карте, показывает, кого и сколько раз ретвитил пользователь, считает статистику по устройствам, с которых писались твиты, а также по времени их публикации. Но за счет того, что это open source инструмент, его функционал всегда можно расширить самому.
Рассматривать, как использовать программу, не будем — все отлично показано в официальном видео, после просмотра которого не должно остаться никаких вопросов по поводу работы с инструментом.
fbStalker
Еще два инструмента, которые менее известны, но обладают сильным функционалом и заслуживают твоего внимания, — fbStalker и geoStalker.
fbStalker предназначен для сбора информации о пользователе на основе его Facebook-профиля. Позволяет выцепить следующие данные:
видео, фото, посты пользователя;
кто и сколько раз лайкнул его записи;
геопривязки фоток;
статистика комментариев к его записям и фотографиям;
время, в которое он обычно бывает в онлайне.
Для работы данного инструмента тебе понадобится Google Chrome, ChromeDriver, который устанавливается следующим образом:
wget [DLMURL]https://goo.gl/Kvh33W[/DLMURL]
unzip chromedriver_linux32_23.0.1240.0.zip
cp chromedriver /usr/bin/chromedriver
chmod 777 /usr/bin/chromedriver
Помимо этого, понадобится установленный Python 2.7, а также pip для установки следующих пакетов:
pip install pytz
pip install tzlocal
pip install termcolor
pip install selenium
pip install requests --upgrade
pip install beautifulsoup4
И наконец, понадобится библиотека для парсинга GraphML-файлов:
git clone [DLMURL]https://github.com/hadim/pygraphml.git[/DLMURL]
cd pygraphml
python2.7 setup.py install
После этого можно будет поправить `fbstalker.py`, указав там свое мыло, пароль, имя пользователя, и приступать к поиску. Пользоваться тулзой достаточно просто:
python fbstalker.py -user [имя интересующего пользователя]
geoStalker
geoStalker значительно интереснее. Он собирает информацию по координатам, которые ты ему передал. Например:
местные Wi-Fi-точки на основе базы `wigle.net` (в частности, их `essid`, `bssid`, `geo`);
чекины из Foursquare;
Instagram- и Flickr-аккаунты, с которых постились фотки с привязкой к этим координатам;
все твиты, сделанные в этом районе.
Для работы инструмента, как и в предыдущем случае, понадобится Chrome & ChromeDriver, Python 2.7, pip (для установки следующих пакетов: google, python-instagram, pygoogle, geopy, lxml, oauth2, python-linkedin, pygeocoder, selenium, termcolor, pysqlite, TwitterSearch, foursquare), а также pygraphml и gdata:
git clone [DLMURL]https://github.com/hadim/pygraphml.git[/DLMURL]
cd pygraphml
python2.7 setup.py install
wget https://gdata-python-client.googlecode. ... .18.tar.gz
tar xvfz gdata-2.0.18.tar.gz
cd gdata-2.0.18
python2.7 setup.py install
После этого редактируем `geostalker.py`, заполняя все необходимые API-ключи и access-токены (если для какой-либо соцсети эти данные не будут указаны, то она просто не будет участвовать в поиске). После чего запускаем инструмент командой `sudo python2.7 geostalker.py` и указываем адрес или координаты. В результате все данные собираются и размещаются на Google-карте, а также сохраняются в HTML-файл.
Переходим к действиям
До этого речь шла о готовых инструментах. В большинстве случаев их функционала будет не хватать и придется либо их дорабатывать, либо писать свои тулзы — все популярные соцсети предоставляют свои API. Обычно они предстают в виде отдельного поддомена, на который мы шлем GET-запросы, а в ответ получаем XML/JSON-ответы. Например, для «Инстаграма» это `api.instagram.com`, для «Контакта» — `api.vk.com`. Конечно, у большинства таких API есть свои библиотеки функций для работы с ними, но мы ведь хотим разобраться, как это работает, да и утяжелять скрипт лишними внешними библиотеками из-за одной-двух функций не комильфо. Итак, давай возьмем и напишем собственный инструмент, который бы позволял искать фотографии из ВК и «Инстаграма» по заданным координатам и промежутку времени.
Используя документацию к API VK и Instagram, составляем запросы для получения списка фотографий по географической информации и времени.
Instagram API Request:
url = "https://api.instagram.com/v1/media/search?"
+ "lat=" + location_latitude
+ "&lng=" + location_longitude
+ "&distance=" + distance
+ "&min_timestamp=" + timestamp
+ "&max_timestamp=" + (timestamp + date_increment)
+ "&access_token=" + access_token
Vkontakte API Request:
url = "https://api.vk.com/method/photos.search?"
+ "lat=" + location_latitude
+ "&long=" + location_longitude
+ "&count=" + 100
+ "&radius=" + distance
+ "&start_time=" + timestamp
+ "&end_time=" + (timestamp + date_increment)
Здесь используемые переменные:
location_latitude — географическая широта;
location_longitude — географическая долгота;
distance — радиус поиска;
timestamp — начальная граница интервала времени;
date_increment — количество секунд от начальной до конечной границы интервала времени;
access_token — токен разработчика.
Как выяснилось, для доступа к Instagram API требуется access_token. Получить его несложно, но придется немного заморочиться (смотри врезку). Контакт же более лояльно относится к незнакомцам, что очень хорошо для нас.
Получение Instagram Access Token
Для начала регистрируешься в инстаграме. После регистрации переходишь по следующей ссылке:
instagram.com/developer/clients/manage
Жмешь **Register a New Client**. Вводишь номер телефона, ждешь эсэмэску и вводишь код. В открывшемся окне создания нового клиента важные для нас поля нужно заполнить следующим образом:
OAuth redirect_uri: localhost
Disable implicit OAuth: галочка должна быть снята
Остальные поля заполняются произвольно. Как только все заполнил, создавай нового клиента. Теперь нужно получить токен. Для этого впиши в адресную строку браузера следующий URL:
[DLMURL]https://instagram.com/oauth/authorize/?client_id=[/DLMURL][CLIENT_ID]&redirect_uri=https://localhost/&response_type=token
где вместо [CLIENT_ID] укажи Client ID созданного тобой клиента. После этого делай переход по получившейся ссылке, и если ты сделал все правильно, то тебя переадресует на localhost и в адресной строке как раз будет написан Access Token.
https://localhost/#access_token=[Access Token]
Более подробно про этот метод получения токена можешь почитать по следующей ссылке: jelled.com/instagram/access-token.
Автоматизируем процесс
Итак, мы научились составлять нужные запросы, но вручную разбирать ответ сервера (в виде JSON/XML) — не самое крутое занятие. Гораздо удобнее сделать небольшой скриптик, который будет делать это за нас. Использовать мы будем опять же Python 2.7. Логика следующая: мы ищем все фото, которые попадают в заданный радиус относительно заданных координат в заданный промежуток времени. Но учитывай один очень важный момент — выводится ограниченное количество фотографий. Поэтому для большого промежутка времени придется делать несколько запросов с промежуточными интервалами времени (как раз date_increment). Также учитывай погрешность координат и не указывай радиус в несколько метров. И не забывай, что время нужно указывать в timestamp.
Начинаем кодить. Для начала подключим все необходимые нам библиотеки:
import httplib
import urllib
import json
import datetime
Пишем функции для получения данных с API через HTTPS. С помощью переданных аргументов функции мы составляем GET-запрос и возвращаем ответ сервера строкой.
def get_instagram(latitude, longitude, distance, min_timestamp, max_timestamp, access_token):
get_request = '/v1/media/search?lat=' + latitude
get_request+= '&lng=' + longitude
get_request += '&distance=' + distance
get_request += '&min_timestamp=' + str(min_timestamp)
get_request += '&max_timestamp=' + str(max_timestamp)
get_request += '&access_token=' + access_token
local_connect = httplib.HTTPSConnection('api.instagram.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
def get_vk(latitude, longitude, distance, min_timestamp, max_timestamp):
get_request = '/method/photos.search?lat=' + location_latitude
get_request+= '&long=' + location_longitude
get_request+= '&count=100'
get_request+= '&radius=' + distance
get_request+= '&start_time=' + str(min_timestamp)
get_request+= '&end_time=' + str(max_timestamp)
local_connect = httplib.HTTPSConnection('api.vk.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
Еще находим небольшую функцию конвертации timestamp в человеческий вид:
def timestamptodate(timestamp):
return datetime.datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d %H:%M:%S')+' UTC'
Теперь пишем основную логику поиска картинок, предварительно разбив временной отрезок на части, результаты сохраняем в HTML-файл. Функция выглядит громоздко, но основную сложность в ней составляет разбиение временного интервала на блоки. В остальном это обычный парсинг JSON и сохранение нужных данных в HTML.
def parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, access_token):
print 'Starting parse instagram..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('instagram_'+location_latitude+location_longitude+'.html','w')
file_inst.write('<html>')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
local_buffer = get_instagram(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp, access_token)
instagram_json = json.loads(local_buffer)
for local_i in instagram_json['data']:
file_inst.write('<br>')
file_inst.write('<img src='+local_i['images']['standard_resolution']['url']+'><br>')
file_inst.write(timestamptodate(int(local_i['created_time']))+'<br>')
file_inst.write(local_i['link']+'<br>')
file_inst.write('<br>')
local_min_timestamp = local_max_timestamp
file_inst.write('</html>')
file_inst.close()
HTML-формат выбран не просто так. Он позволяет нам не сохранять картинки отдельно, а лишь указать ссылки на них. При запуске страницы результаты в браузере картинки автоматически подгрузятся.
Пишем точно такую же функцию для «Контакта».
def parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment):
print 'Starting parse vkontakte..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('vk_'+location_latitude+location_longitude+'.html','w')
file_inst.write('<html>')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
vk_json = json.loads(get_vk(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp))
for local_i in vk_json['response']:
if type(local_i) is int:
continue
file_inst.write('<br>')
file_inst.write('<img src='+local_i['src_big']+'><br>')
file_inst.write(timestamptodate(int(local_i['created']))+'<br>')
file_inst.write('https://vk.com/id'+str(local_i['owner_id'])+'<br>')
file_inst.write('<br>')
local_min_timestamp = local_max_timestamp
file_inst.write('</html>')
file_inst.close()
И конечно же, сами вызовы функций:
parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, instagram_access_token)
parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment)
Результат работы нашего скрипта в консоли
Один из результатов парсинга Инстаграма
Результат парсинга «Контакта»
Боевое крещение
Скрипт готов, осталось его только опробовать в действии. И тут мне пришла в голову одна идея. Те, кто был на PHD’14, наверняка запомнили очень симпатичных промодевочек от Mail.Ru. Что ж, давай попробуем наверстать упущенное — найти их и познакомиться.
Собственно, что мы знаем об PHD14:
место проведения — Digital October — 55.740701,37.609161;
дата проведения — 21–22 мая 2014 года — 1400619600–1400792400.
Получаем следующий набор данных:
location_latitude = '55.740701'
location_longitude = '37.609161'
distance = '100'
min_timestamp = 1400619600
max_timestamp = 1400792400
date_increment = 60*60*3 # every 3 hours
instagram_access_token = [Access Token]
Полезные советы
Если в результате работы скрипта фотографий будет слишком мало, можешь пробовать изменять переменную `date_increment`, поскольку именно она отвечает за интервалы времени, по которым собираются фотографии. Если место популярное, то и интервалы должны быть частыми (уменьшаем `date_increment)`, если же место глухое и фотографии публикуют раз в месяц, то и сбор фотографий интервалами в час не имеет смысла (увеличиваем `date_increment`).
Запускаем скрипт и идем разбирать полученные результаты. Ага, одна из девочек выложила фотку, сделанную в зеркале в туалете, с привязкой по координатам! Естественно, API не простил такой ошибки, и вскоре были найдены странички всех остальных промодевочек. Как оказалось, две из них близняшки
.
Та самая фотография промо-девочки с PHD’14, сделанная в туалете
Поучительный пример
В качестве второго примера хочется вспомнить одно из заданий с финала CTF на PHD’14. Собственно, именно после него я заинтересовался данной темой. Суть его заключалась в следующем.
Есть злой хацкер, который разработал некую малварь. Нам дан набор координат и соответствующих им временных меток, из которых он выходил в интернет. Нужно добыть имя и фотку это хацкера. Координаты были следующие:
55.7736147,37.6567926 30 Apr 2014 19:15 MSK;
55.4968379,40.7731697 30 Apr 2014 23:00 MSK;
55.5625259,42.0185773 1 May 2014 00:28 MSK;
55.5399274,42.1926434 1 May 2014 00:46 MSK;
55.5099579,47.4776127 1 May 2014 05:44 MSK;
55.6866654,47.9438484 1 May 2014 06:20 MSK;
55.8419686,48.5611181 1 May 2014 07:10 MSK
Первым делом мы, естественно, посмотрели, каким местам соответствуют эти координаты. Как оказалось, это станции РЖД, причем первая координата — это Казанский вокзал (Москва), а последняя — Зеленый Дол (Зеленодольск). Остальные — это станции между Москвой и Зеленодольском. Получается, что он выходил в интернет из поезда. По времени отправления был найден нужный поезд. Как оказалось, станцией прибытия поезда является Казань. И тут встал главный вопрос: где искать имя и фотку. Логика заключалась в следующем: поскольку требуется найти фотку, то вполне разумно предположить, что искать ее нужно где-то в социальных сетях. Основными целями были выбраны «ВКонтакте», «Фейсбук», «Инстаграм» и «Твиттер». В соревнованиях помимо русских команд участвовали иностранцы, поэтому мы посчитали, что организаторы вряд ли бы выбрали «ВКонтакте». Решено было начать с «Инстаграма».
Никакими скриптами для поиска фотографий по координатам и времени мы тогда не обладали, и пришлось использовать публичные сервисы, умевшие это делать. Как выяснилось, их довольно мало и они предоставляют довольно скудный интерфейс. Спустя сотни просмотренных фотографий на каждой станции движения поезда наконец была найдена нужная.
В итоге, чтобы найти поезд и недостающие станции, а также логику дальнейшего поиска, понадобилось не больше часа. А вот на поиск нужной фотографии — очень много времени. Это еще раз подчеркивает, насколько важно иметь правильные и удобные программы в своем арсенале.
WWW
Исходный код рассмотренного скрипта ты можешь найти в моем Bitbucket-репозитории
Выводы
Статья подошла к завершению, и настало время делать вывод. А вывод простой: заливать фотографии с геопривязкой нужно обдуманно. Конкурентные разведчики готовы зацепиться за любую возможность получить новую информацию, и API социальных сетей им в этом могут очень неплохо помочь. Когда писал эту статью, я изучил еще несколько сервисов, в том числе Twitter, Facebook и LinkedIn, — есть ли подобный функционал. Положительные результаты дал только «Твиттер», что, несомненно, радует. А вот Facebook и LinkedIn огорчили, хотя еще не все потеряно и, возможно, в будущем они расширят свои API. В общем, будь внимательнее, выкладывая свои фото с геопривязкой, — вдруг их найдет кто-нибудь не тот.
Впервые опубликовано в журнале «Хакер» от 02/2015.
Автор: Аркадий Литвиненко (@Betep
k)https://m.habrahabr.ru/company/xakep/blog/254129/